
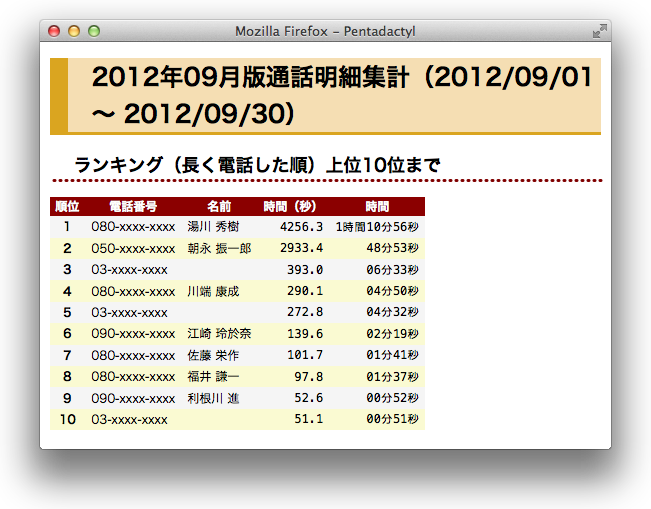
Softbank 携帯は月々 100 円を支払うとウェブサイトより通話明細を得ることが出来ます。しかしこれがまあ、使いにくい!
- PDF 形式でしかダウンロードできない。
- 1 ページ当たり 10 件ずつページングしてあって網羅的に見ることが難しい。
とまあ、完全に社用として使ってる携帯の明細を、経理に提出するくらいにしか使えないわけですね。単純に、「先月誰に多くかけたのかな〜?」と個人が使うことは考えていないのです。
だったら使いやすくしてやろうと言うことで、スクレーピングして明細を取得するプログラムを書きました。
使い方
delphinus35/getCallDetailFromMySoftbank · GitHub
https://github.com/delphinus35/getCallDetailFromMySoftbank
ここに一式置いてあります。必要なモジュールは適宜インストールしてください。以下のようにして使います。
$ ./get_call_detail_from_my_softbank.pl -u 09012345678 -p MyPaSsWoRd
--username, -u- ユーザー名。つまり電話番号。
--password, -p- パスワード。My Softbank にログインできるものです。これが設定していないとそもそも使えません。
この指定だと、カレントディレクトリに mysoftbank_detail_YYYYMM.csv の形式でファイルが出力されます。
他にはこんなオプションが指定できます。
--ym=YYYYMM- 出力する明細の年月を指定します。たとえば、「2012年10月」分の明細が欲しいときは
201210と指定します。 --type, -t=json,yaml,csv,excel,html- 出力する形式を指定します。標準では CSV 形式です。最初の 4 つ(JSON, YAML, CSV, Excel)は基本的にサイトのデータをそのまま並べただけですが、HTML の場合は一番始めに挙げたスクリーンショットのようにちょっとだけ統計情報を載せます。
csv,excel,htmlの場合はカレントディレクトリにmysoftbank_detail_YYYYMMで始まるファイルを作りますが、json,yamlの場合はファイルを作りません。標準出力に生のデータをそのまま吐きます。 --vcard=sample.vcf- アドレス帳を指定すると電話番号と別に相手先の名前を書き出します。
--verbose=0, 1, 2- デバッグメッセージのレベルを指定します。
0を指定すると、完全に沈黙します。(標準は1です)
アドレス帳に指定する .vcf ファイルは Mac なら「連絡先」、Windows なら「Outlook」などから生成できます。やり方はこの辺を参照してください。
【Mac】Address Book 6.x: vCard を書き出す/読み込む
http://support.apple.com/kb/PH4655?viewlocale=ja_JP【Windows】連絡先を vCard (.vcf ファイル) として送信および保存する – Outlook – Office.com
http://office.microsoft.com/ja-jp/outlook-help/HA010243189.aspx
iCloud を使ってるならばブラウザからも出力できますね。この方法なら OS を選びません。
iCloud: 連絡先情報をvCardとして書き出す
http://support.apple.com/kb/PH3606?viewlocale=ja_JP&locale=ja_JP
技術的なこと
そういえば以前、PASMO の利用履歴を得るスクリプト を作ったときに、「次回は scraper コマンドを入れ子にすることでこれを解決しよう。(続く)」と書いて完全に放置していたことを思い出しました。
今更ですが、今回のスクリプトから Web::Scraper の部分を解説してみましょう。
Web::Scraper による複雑な解析
return scraper {
process
'//form[@name="detailsCallsActionForm"]//p[@class="prev"]/span[@class=""]/a',
prev_month_link => '@href';
process '//input[@name="billYm"]', ym => '@value';
process '//ul[@class="navi_view_list"]/li',
'links[]' => +{
class => '@class',
page => scraper {
process '//a' , number => ['@href' , \&get_page_number];
process '//span' , text => 'TEXT';
},
link => scraper { process '//a', url => '@href'; },
};
process '//table[@class="contract-info hasthead"]/tbody/tr',
'rows[]' => scraper {
process '//td[1]', date => ['TEXT', \&trim];
process '//td[2]', time => ['TEXT', \&trim];
process '//td[3]', call_time => ['TEXT', \&trim];
process '//td[4]', phone_number => ['TEXT', \&trim];
process '//td[5]', option_service => ['TEXT', \&trim];
process '//td[6]', call_zone => ['TEXT', \&trim];
process '//td[7]', charge => ['TEXT', \&delete_comma];
process '//td[8]', discount_type => ['TEXT', \&trim];
process '//td[9]', cnote => ['TEXT', \&trim];
};
}->scrape($html);
scraper コマンドから得られるハッシュリファレンスの中身は process コマンドによって作られる key と value の組み合わせです。
process コマンドには引数として scraper コマンドを与えることが出来、こうするとハッシュリファレンスが入れ子になることで各階層ごとに複雑な解析が出来るようになります。
ページリンクの解析
例として、上のコードの 6 行目 〜 14 行目を見てみます。このコードではページングされた明細の各ページのページ番号とリンクを取得しています。
process '//ul[@class="navi_view_list"]/li',
'links[]' => +{
class => '@class',
page => scraper {
process '//a' , number => ['@href' , \&get_page_number];
process '//span' , text => 'TEXT';
},
link => scraper { process '//a', url => '@href'; },
};
まず、1 行目の XPath 式 //ul[@class="navi_view_list"]/li によって表される HTML が取得され、これが links[] に納められます。
links[] はハッシュリファレンスの key に当たります。[] は結果を配列リファレンスで受けとることを示します。
links => [
'<li class="btn_first_page"><span class="disable">...',
'<li class="prev"><span><</span></li>',
'<li class="current"><span>1</span></li>',
'<li><span><a href="/wco/detailsCalls/goPaging/2?billYm=201210">2</a></span></li>',
'<li><span><a href="/wco/detailsCalls/goPaging/3?billYm=201210">3</a></span></li>',
'...',
'...',
]
scraper の入れ子
この時点で links の中には以下のものが含まれています。
- 【先頭ページ】へのリンク
- 【<(一つ前のページ)】へのリンク
- 各ページへのリンク
- 【>(一つ後のページ)】へのリンク
- 【最終ページ】へのリンク
これらをそれぞれ個別に解析していきます。
8 行目 class => '@class',
<li> タグの class を取得します。これが btn_first_pageなら【先頭ページ】へのリンクを表し、prev なら【一つ前のページ】へのリンクだったりするわけです。
9 行目 page => scraper { ... },
引数を scraper コマンドに渡しています。これが scraper の入れ子です。
ここでは、与えられた <li> タグを更に解析し、中から <a>タグと <span> タグを抜き出しています。
process '//a' , number => ['@href' , \&get_page_number];
これは、<a> タグから href 属性を抜き出し、それを get_page_number()サブルーチンに渡すという意味です。
sub get_page_number {
($_) = m!goPaging/(\d+)!;
}
単純に正規表現を使って数字を一つ得ているだけですね。
もう一つの行は単に <span> タグの中身を得ているだけです。
process '//span' , text => 'TEXT';
この部分から次のようなハッシュリファレンスが得られます。
page => +{number => '1', text => '先頭ページ'},
page => +{number => '', text => '1'},
page => +{number => '2', text => '2'},
...
13 行目 link => scraper { process '//a', url => '@href'; },
9 行目 〜 12 行目に比べるとずいぶん簡単ですね。引数から <a> タグを抜き出し、その href 属性を link に納めています。
link => +{url => 'http://...'},
得られた結果
まとめると、6 行目 〜 14 行目からは以下のような配列リファレンスが得られます。
links => [
+{
class => 'btn_first_page',
page => +{number => '1', text => '先頭ページ'},
link => +{url => 'http://...'},
+{
class => 'current',
page => +{number => '', text => '1'},
link => +{url => 'http://...'},
},
+{
class => '',
page => +{number => '2', text => '2'},
link => +{url => 'http://...'},
},
...
],
ふ〜。長かった。これでもまだ一部です。でも後はこれらを応用すれば読み解けるでしょう。
まとめ
昔々、素の HTML を正規表現を使って解析したり、それから少し後には HTML::Parser や HTML::TreeBuilder などを使っていちいち解析していたことを思えば、Web::Scraper によるものは遙かに洗練されていますね。
WWW::Mechanize を使えばたいていのページにアクセスできますし、それでも難しい、Javascript を駆使するようなサイトは Selenium を使って実際のブラウザを動かして結果を得ることも出来ます。
最近のサービスは JSON その他の API で利用者にとっても使いやすいものを目指しているところが多いですが、今回のような昔ながらの(?)サイトには今回のような手はまだまだ有効ですね。