
【Perl】WWW::Mechanize と Web::Scraper で PASMO の利用履歴を得る(その1)
https://blog.delphinus.dev/2010/10/get-pasmo-history-with-perl.html
前回に引き続き、ページの解析を行う。まずは Firebug をインストールしておこう。
Firebug :: Add-ons for Firefox
https://addons.mozilla.org/ja/firefox/addon/1843/
Firebug で確認

前回得られたページを sample.html と言うファイル名で保存しているとする。このページを Firefox で開いて中身を確認する

“SF 残額履歴”欄の適当な行を右クリックして“要素を調査”をクリックすると、該当する場所が Firebug で表示される。
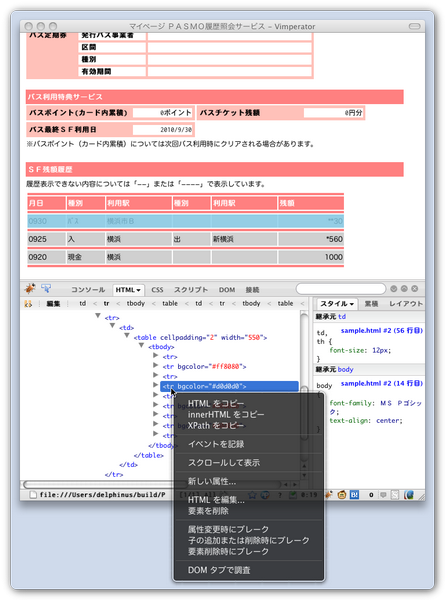
図にあるように <tr> タグに該当する部分を右クリックし“XPath をコピー”を選ぶと、目的の項目を表す XPath が得られる。
この例ではこのとき、クリップボードに以下のものが入っているはずだ。
/html/body/form/table[2]/tbody/tr[13]/td/table/tbody/tr[4]
scraper コマンドで確認
以下の記述は次のサイトを参考にした。
use Web::Scraper; – 今日のCPANモジュール
http://e8y.net/mag/013-web-scraper/
Web::Scraper モジュールをインストールすると、scraper と言うコマンドラインユーティリティが一緒にインストールされる。これはコマンドラインから対話的に Web::Scraper の試験ができる優れものだ。プロンプトから次のように入力して起動する。
$ scraper sample.html scraper>
前節でコピーした XPath 式を使って次のように入力する。
scraper> process '/html/body/form/table[2]/tbody/tr[13]/td/table/tbody/tr[4]', WARN scraper>
これは、読み込んだ HTML を指定した XPath 式で解析し、該当するタグを表示する命令だ。しかし、このときは何も表示されないだろう。なぜなら、XPath 式に含まれる“<tbody>”タグは Firefox が勝手に挿入したものなのだ。ちょっといじってもう一度実行する。
scraper> process '/html/body/form/table[2]/tr[13]/td/table/tr[4]', WARN <tr bgcolor="#D0D0D0"><td>0930</td><td>バス</td><td>横浜市B</td><td> </td><td></td><td align="right">**30</td></tr> scraper>
今度はきちんと表示された。この後に何度も試して、なるべく簡便な XPath 式になるようにしてみる。
scraper> process '//tr[@bgcolor="#D0D0D0"]', WARN <tr bgcolor="#D0D0D0"><td>0930</td><td>バス</td><td>横浜市B</td><td> </td><td></td><td align="right">**30</td></tr> <tr bgcolor="#D0D0D0"><td>0925</td><td>入</td><td>横浜</td><td>出</td><td>新横浜</td><td align="right">*560</td></tr> <tr bgcolor="#D0D0D0"><td>0920</td><td>現金</td><td>横浜</td><td> </td><td></td><td align="right">1000</td></tr> scraper>
該当する <tr> タグには必ず“bgcolor="#D0D0D0"”という属性がついているのでここまで簡単にできた。
process 関数の最後に付いている“WARN”は、実際のスクリプトでは使えない。結果を変数に収納して後から使えるようにする(process 関数の詳しい書式については後述)。
scraper> process '//tr[@bgcolor="#D0D0D0"]', 'items[]' => "HTML" scraper>
“c”コマンドをタイプすると、最後に実行した process コマンドを使った Perl スクリプトが表示される。これをファイルに保存しておこう。
scraper> c ここにコードが表示される scraper>
#!/opt/local/bin/perl
use strict;
use Web::Scraper;
use URI;
my $file = \do { my $file = "sample.html"; open my $fh, $file or die "$file: $!"; join '', <$fh> };
my $scraper = scraper {
process '//tr[@bgcolor="#D0D0D0"]', 'items[]' => "HTML";
};
my $result = $scraper->scrape($file);
use YAML; print Dump $result;
$ perl sample.pl ---items: - '<td>0930</td><td>バス</td><td>横浜市B</td><td> </td><td></td><td align="right">**30</td>' - '<td>0925</td><td>入</td><td>横浜</td><td>出</td><td>新横浜</td><td align="right">*560</td>' - '<td>0920</td><td>現金</td><td>横浜</td><td> </td><td></td><td align="right">1000</td>'
scraper 関数の詳細
Web::Scraper によるスクレイピングは次のようにして行う。
my $result = scraper {
process <CSS式 or XPath式>, '保存先のキー名' => '保存形式';
}->scrape( 解析するHTML );
'保存形式' には次のものを指定できる。
TEXT- 該当するタグに含まれるテキストだけを吐く。通常はこれを使う。
HTML- 該当するタグの HTML コードを丸ごと吐く。
@属性名- 該当するタグの指定された属性値を吐く。
- サブルーチンリファレンス
- 該当するタグの
HTML::Elementオブジェクトインスタンスを引数に与えて実行される。 scrapeコマンド- scrape した結果を更に scrape する。
最後の項目が重要だ。今回は一度目の scrape で得られた以下の結果について、更に <td> タグの中身を配列で得たい。
<tr bgcolor="#D0D0D0"><td>0930</td><td>バス</td><td>横浜市B</td><td> </td><td></td><td align="right">**30</td></tr> <tr bgcolor="#D0D0D0"><td>0925</td><td>入</td><td>横浜</td><td>出</td><td>新横浜</td><td align="right">*560</td></tr> <tr bgcolor="#D0D0D0"><td>0920</td><td>現金</td><td>横浜</td><td> </td><td></td><td align="right">1000</td></tr>
次回は scraper コマンドを入れ子にすることでこれを解決しよう。(続く)